No More Hustleporn: 2022: A Year in Review (ML Papers Edition)
Tweet by elvis
https://twitter.com/omarsar0
@omarsar0:
2022: A Year in Review (ML Papers Edition)
In this thread, let's take a look at some of the top trending ML papers of 2022 ↓

@omarsar0:
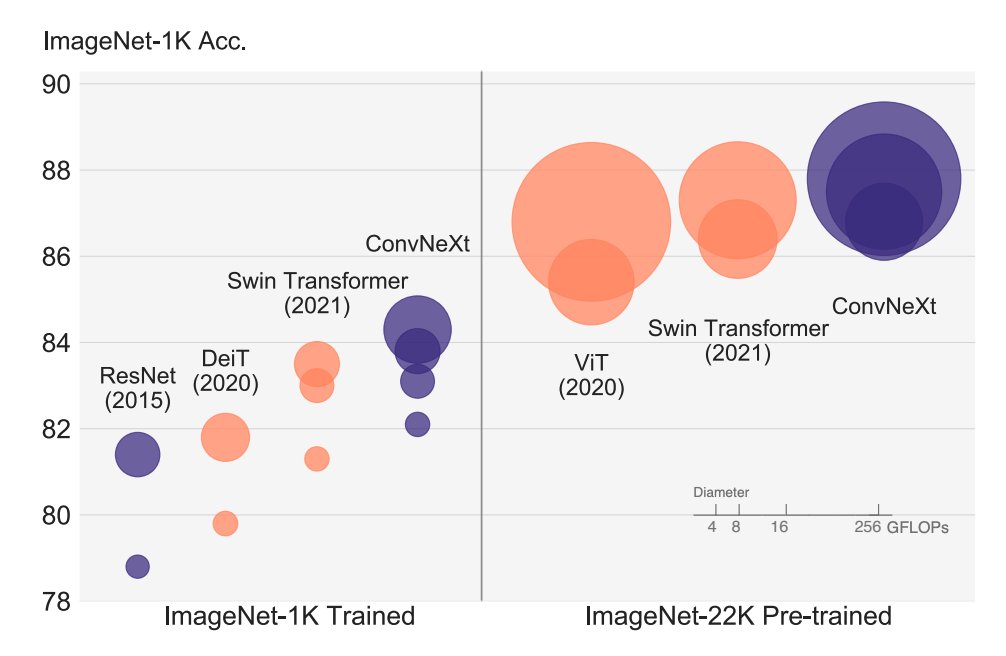
1) A ConvNet for the 2020s - Liu et al.
Vision Transformers took off this year but this work proposes ConvNeXt to reexamine the design spaces and test the limits of a pure ConvNet on several vision tasks. The ConvNets vs. Transformers debate continues.
arxiv.org/abs/2201.03545…
@omarsar0:
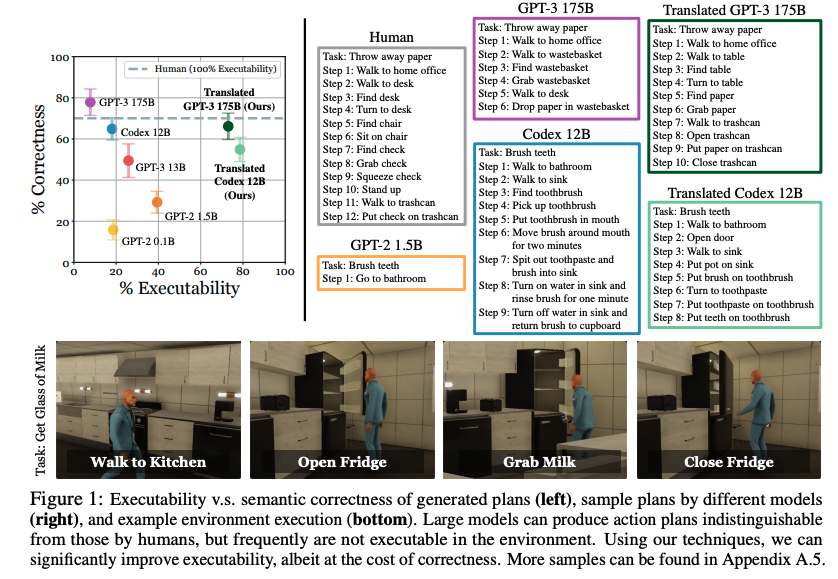
2) Language Models as Zero-Shot Planners - Huang et al.
Studies the possibility of grounding high-level tasks to actionable steps for embodied agents. Pre-trained LLMs are used to extract knowledge to perform common-sense grounding by planning actions.
arxiv.org/abs/2201.07207…
@omarsar0:
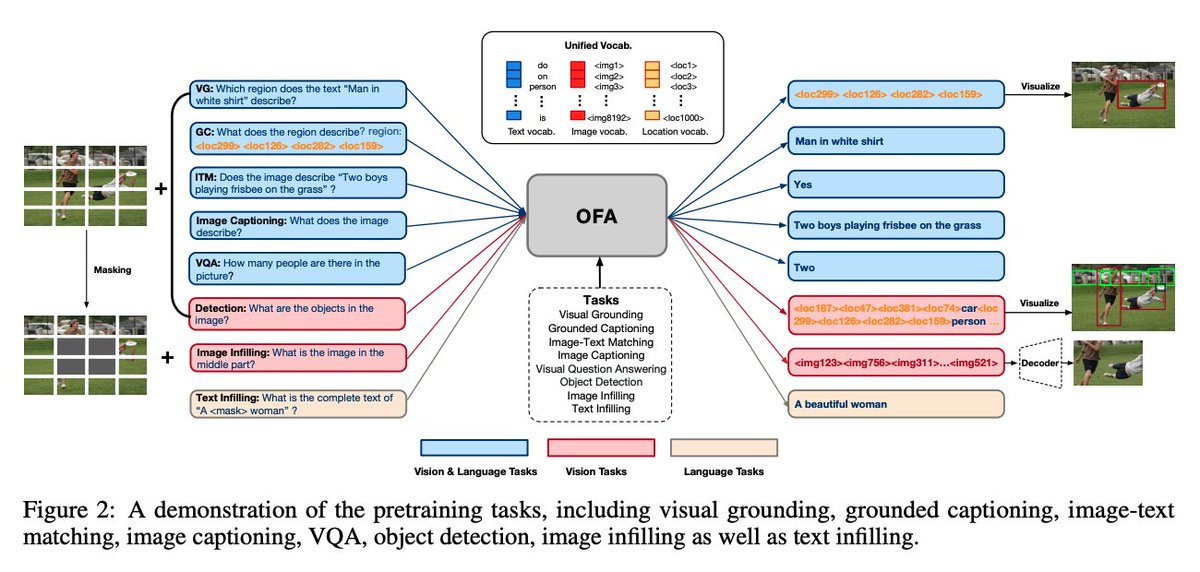
3) OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework - Yang et al.
Introduces a unified paradigm for effective multimodal pre-training that support all kinds of uni-modal and cross-modal tasks.
arxiv.org/abs/2202.03052…
@omarsar0:
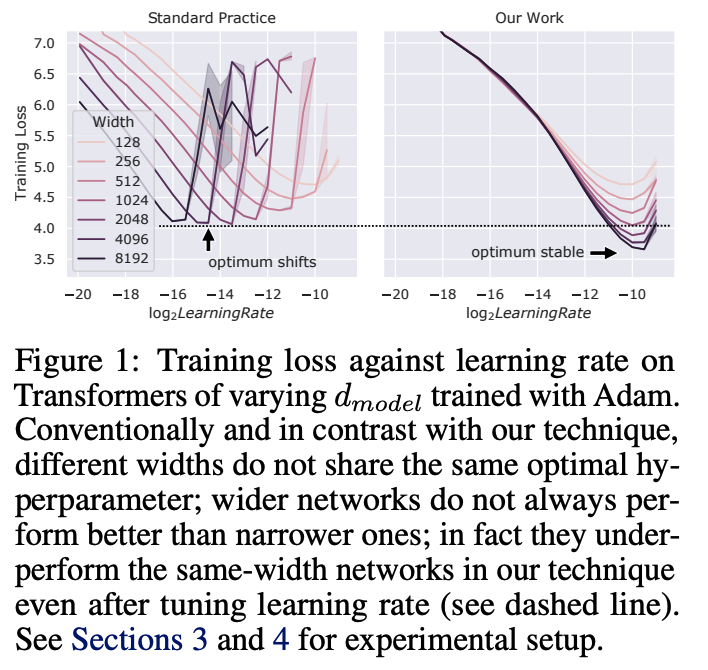
4) Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer - Yang et al.
Proposes a new paradigm for more efficiently tuning large neural networks via zero-shot hyperparameter tuning.
arxiv.org/abs/2203.03466…
@omarsar0:
5) OPT: Open Pre-trained Transformer Language Models - Zhang et al.
An open pre-trained transformer-based language model called OPT; follows other open-sourcing LLM efforts such as GPT-Neo; model sizes range from 125M to 175B parameters.
arxiv.org/abs/2205.01068…

@omarsar0:
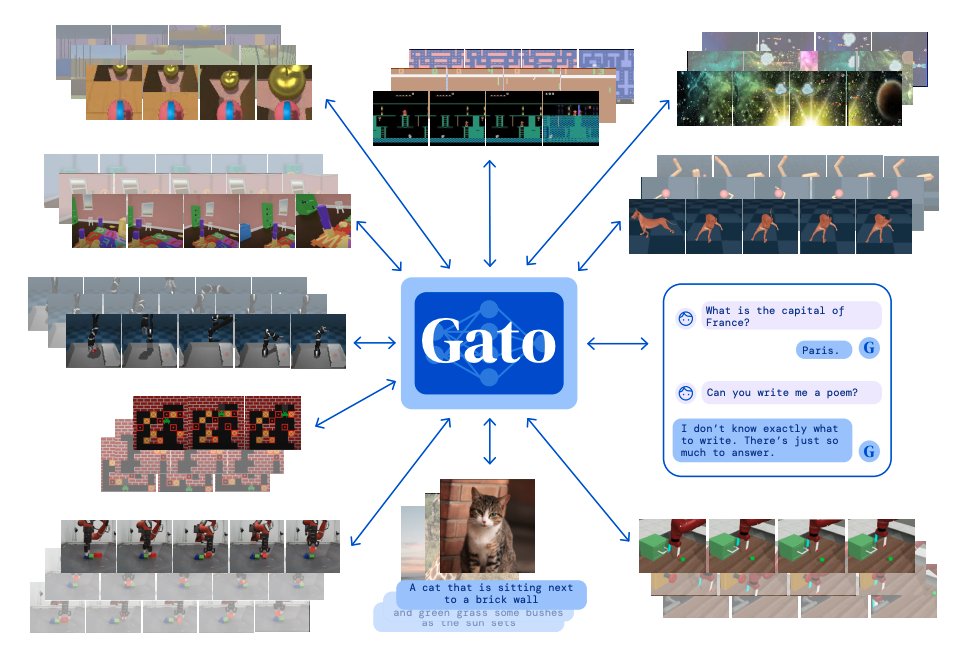
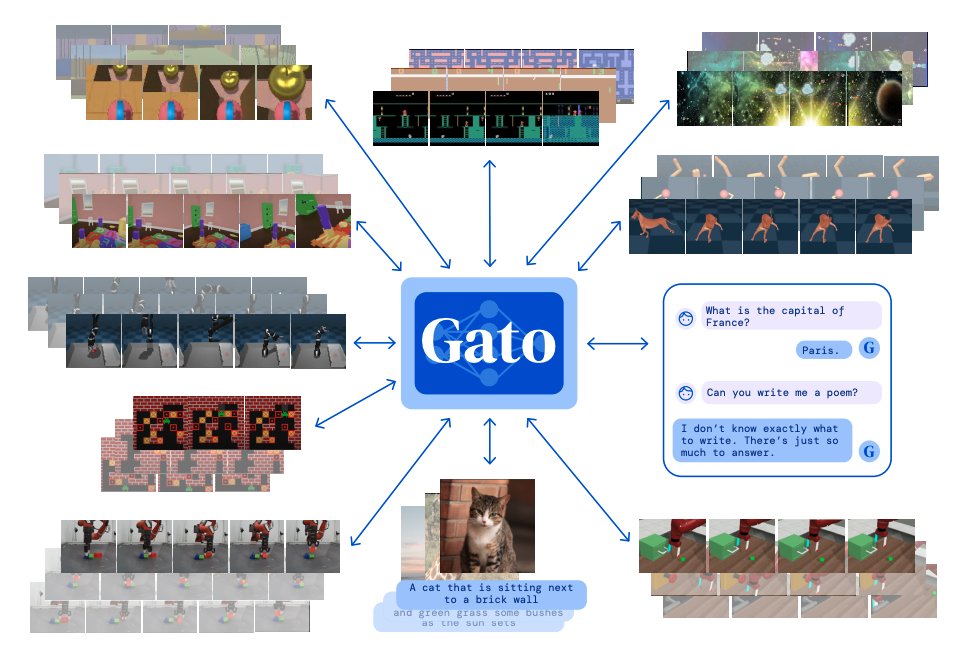
6) Gato - DeepMind
Gato is an agent built to work as a multi-modal, multi-task, multi-embodiment generalist policy; it performs all sorts of general tasks ranging from playing Atari to chatting to stacking blocks with a real robot arm.
arxiv.org/abs/2205.06175…
@omarsar0:
7) Solving Quantitative Reasoning Problems with Language Models
Introduces Minerva, a large language model pretrained on general natural language data and further trained on technical content; evaluated on several tasks requiring quantitative reasoning.
arxiv.org/abs/2206.14858

@omarsar0:
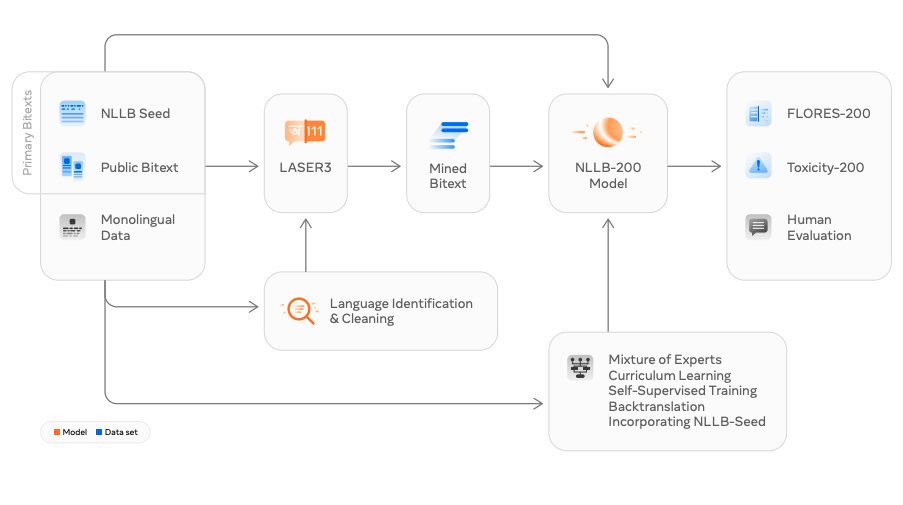
8) No Language Left Behind (NLLB) - Meta AI
Introduces a massive translation model (NLLB-200), capable of translating between 200 languages.
arxiv.org/abs/2207.04672…
@omarsar0:
9) Stable Diffusion - Rombach et al.
A text-to-image model to generate detailed images conditioned on text descriptions; can be applied to other tasks such as inpainting, outpainting, and generating image-to-image translations guided by a text prompt.
github.com/CompVis/stable…
@omarsar0:
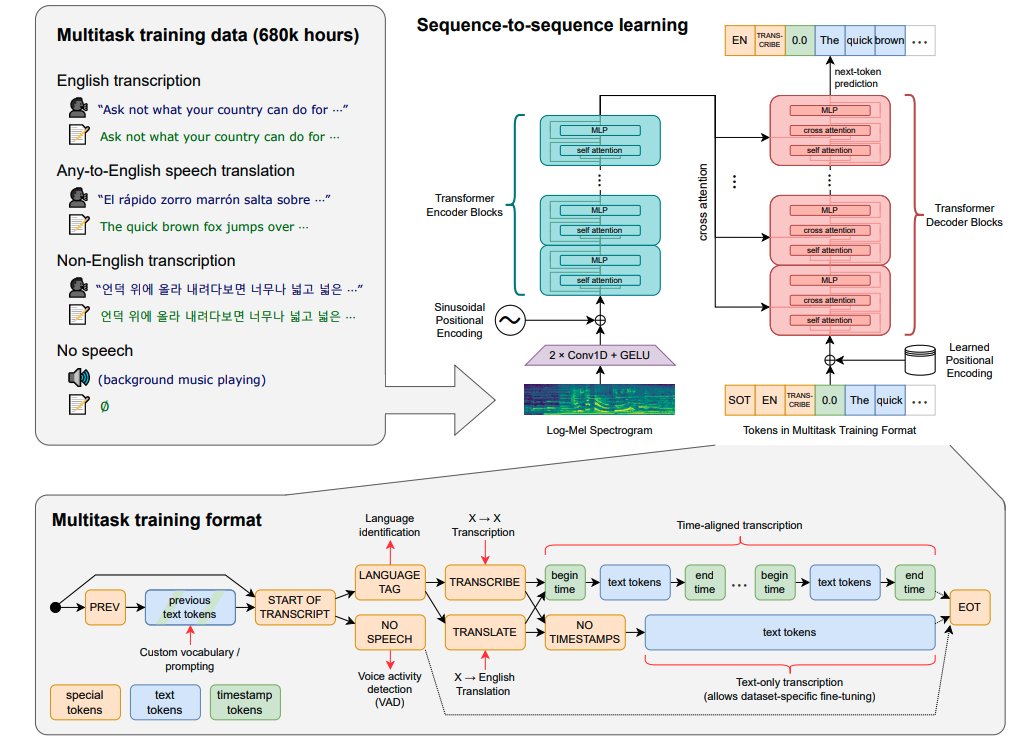
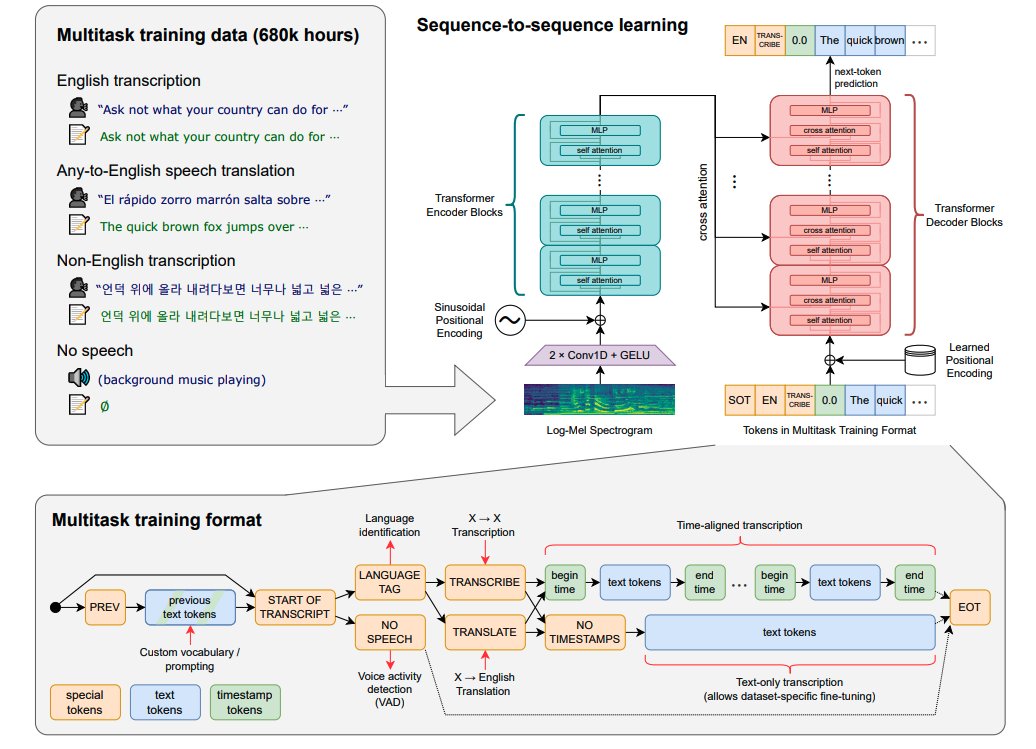
10) Whisper - OpenAI
An open-source model called Whisper that approaches human-level robustness and accuracy in English speech recognition.
arxiv.org/abs/2212.04356
@omarsar0:
11) Make-A-Video (Singer et al)
Introduces a state-of-the-art text-to-video model that can generate videos from a text prompt.
arxiv.org/abs/2209.14792
@omarsar0:
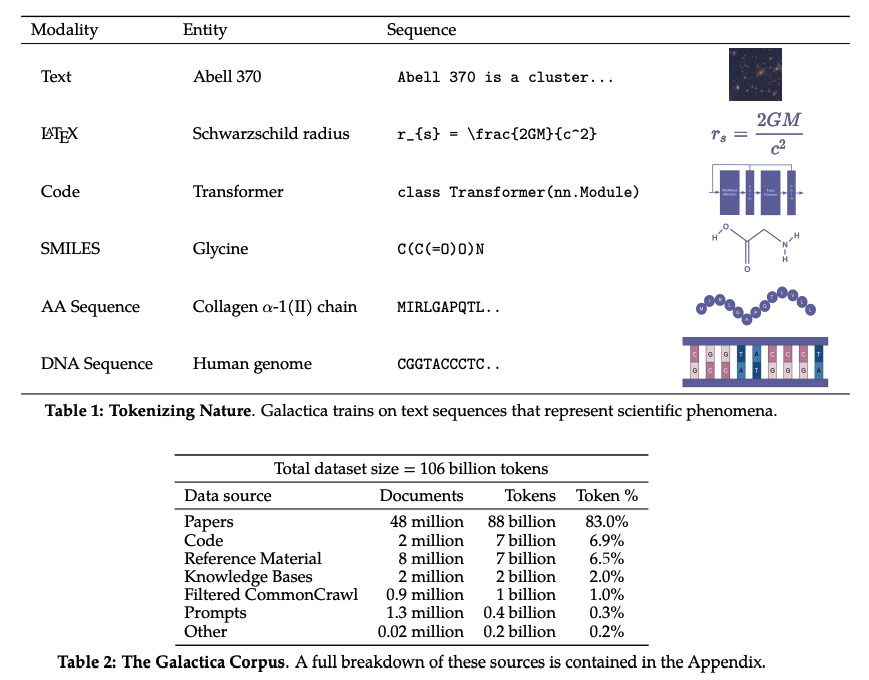
12) Galactica - A large language model for science (Ross et al)
A large language model for the science domain trained on a massive scientific corpus.
arxiv.org/abs/2211.09085
@omarsar0:
The list is non-exhaustive. I tried to highlight trending papers for each month of the year based on trends.
Feel free to share your favorite ML papers below. Happy holidays!🎉
One last favor: follow me (
@omarsar0
) to keep track of more exciting ML papers in 2023.